Prerequisites
This documentation assumes that you have a fully functional PredictionIO setup. If you have not installed PredictionIO yet, please follow these instructions.
The following instructions have been tested with IntelliJ IDEA 2018.2.2 Community Edition.
Preparing IntelliJ for Engine Development
Installing IntelliJ Scala Plugin
First of all, you will need to install the Scala plugin if you have not already done so.
Go to the Preferences menu item, and look for Plugins. You should see the following screen.
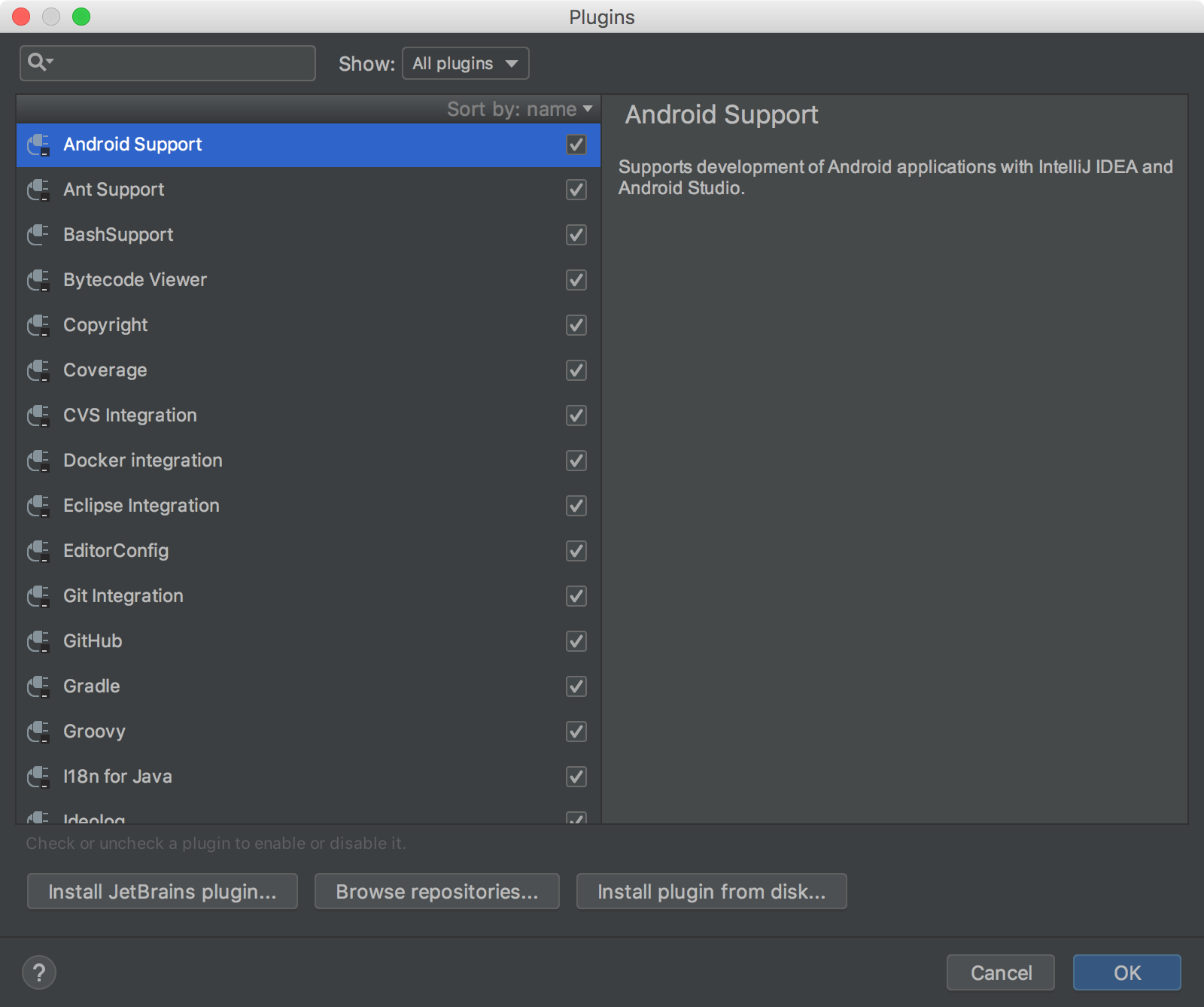
Click Install JetBrains plugin..., the search for Scala. You should arrive at something similar to the following.
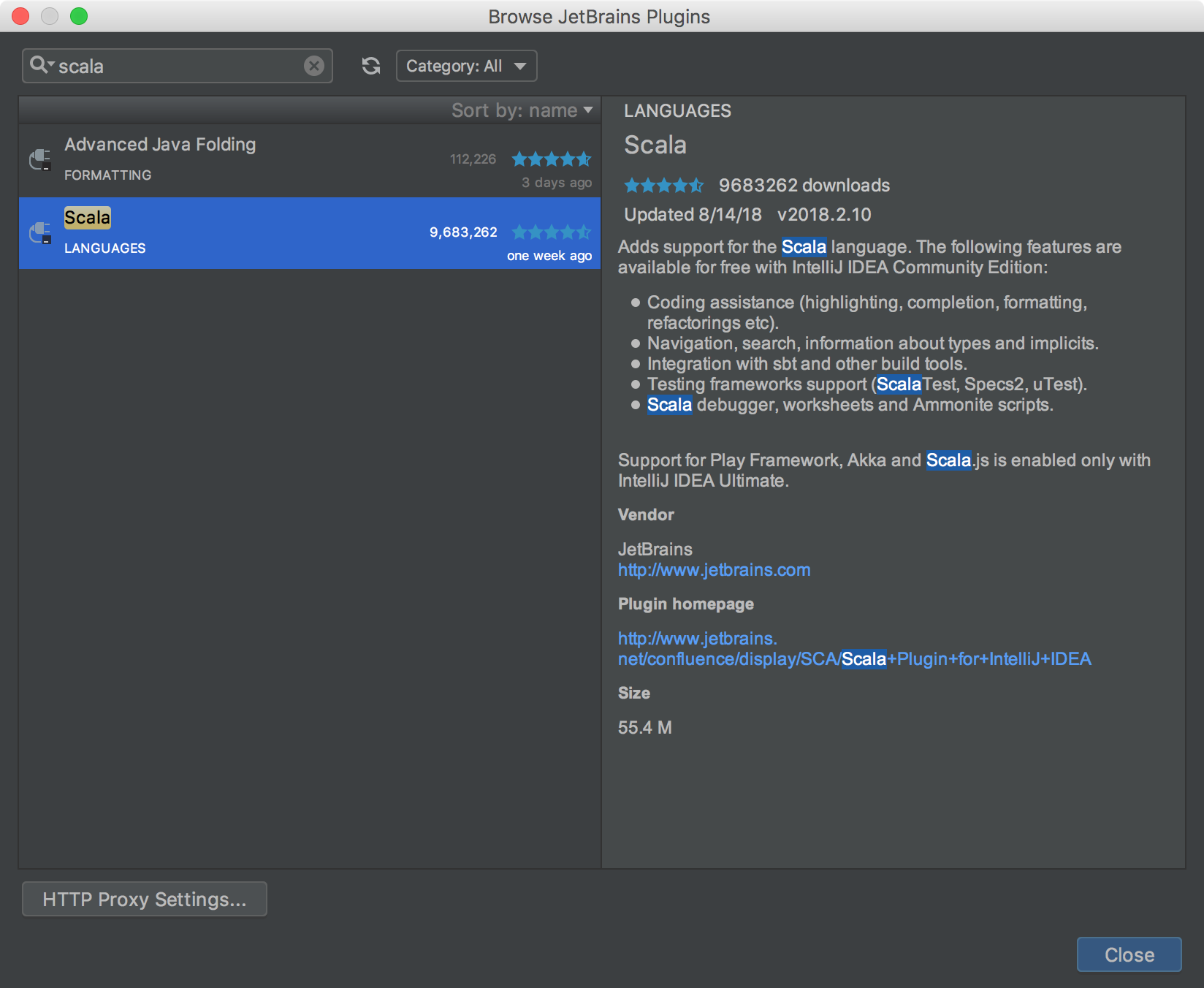
Click the green Install plugin button to install the plugin. Restart IntelliJ IDEA if asked to do so.
Setting Up the Engine Directory
Create an engine directory from a template. This requires that you download a template that you wish to start from or modify.
Follow template install and deploy instructions or go through the Quick Start if you are planning to modify a recommender. Make sure to build, train, and deploy the engine to make sure all is configured properly.
From IntelliJ IDEA, choose File > New > Project from Existing Sources.... When asked to select a directory to import, browse to the engine directory that you downloaded too and proceed. Make sure you pick Import project from external model > SBT, then proceed to finish.
You should be able to build the project at this point. To run and debug your template, continue on to the rest of the steps.
Optional: Issues with Snappy on macOS
If you are running on macOS and run into the following known issue, follow steps in this section.
Edit build.sbt and add the following under libraryDependencies
1 | "org.xerial.snappy" % "snappy-java" % "1.1.1.7" |
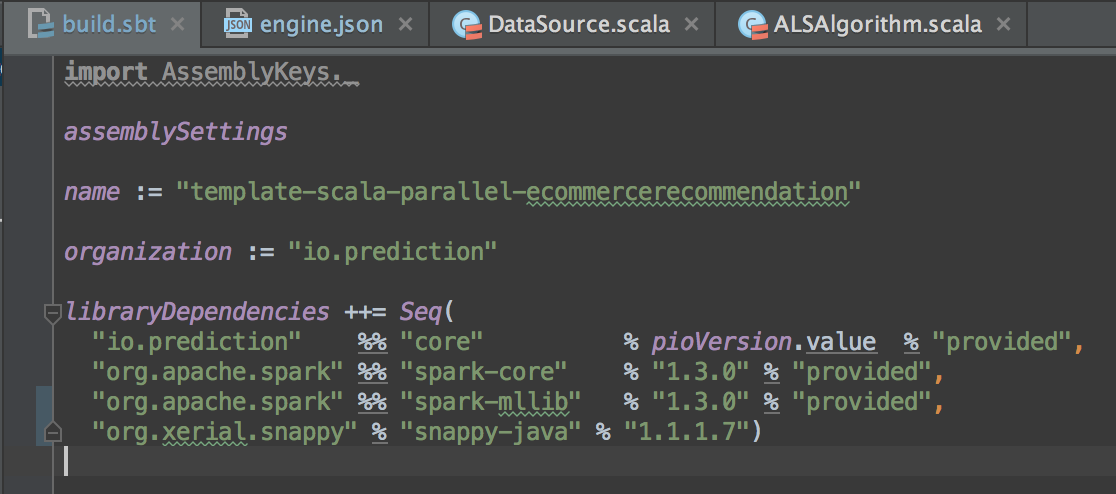
When you are done editing, IntelliJ should prompt you to import new changes, unless you have already enabled auto import. Import this change to make it effective.
Module Settings
Due to the way how pio command sources required classes during runtime, it is necessary to add them manually in module settings for Run/Debug Configurations to work properly.
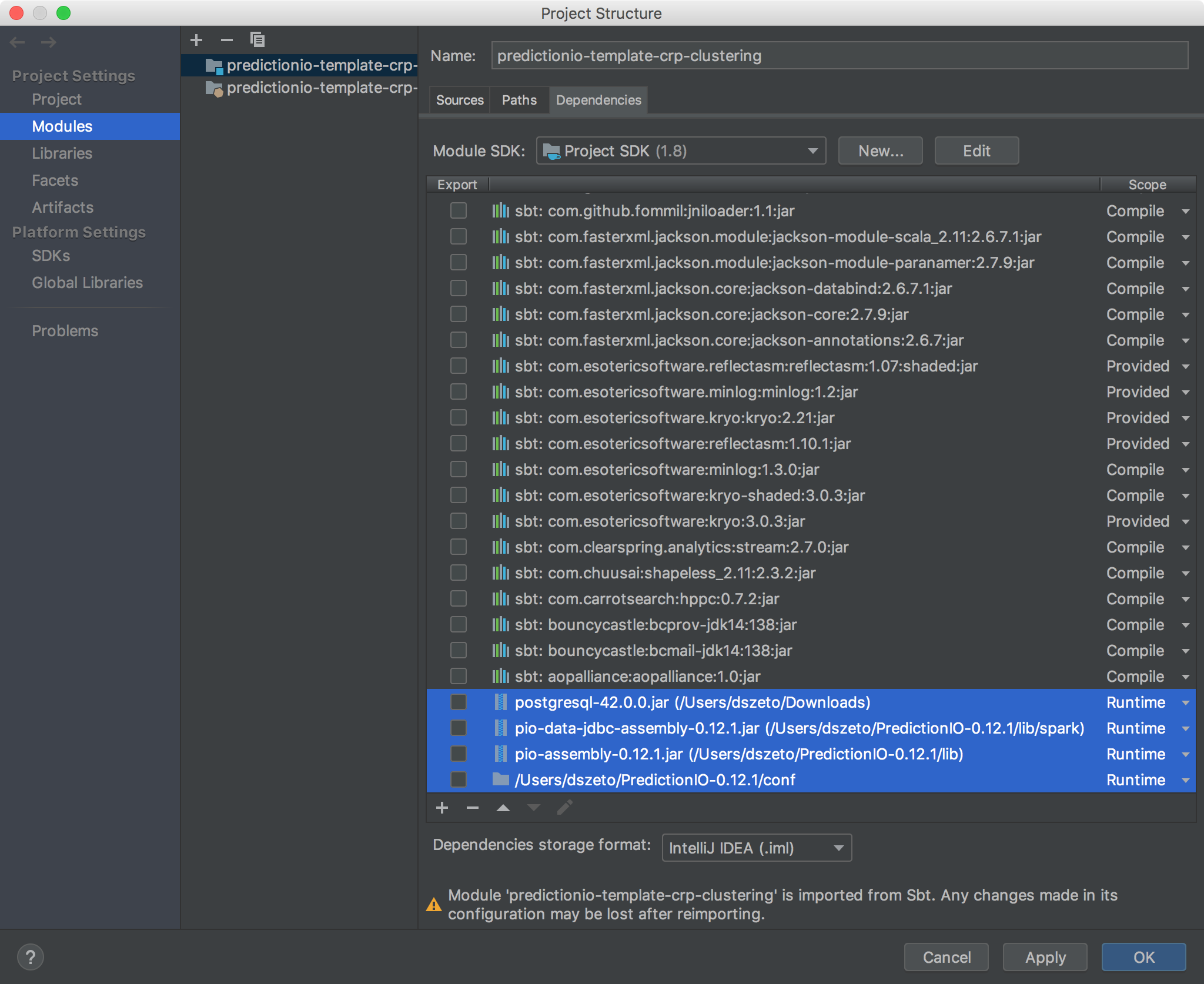
Right click on the project and click Open Module Settings. Hit the + button right below the list of dependencies, and select JARs or directories....
The first JAR that you need to add is the pio-assembly-0.14.0.jar that contains all necessary classes. It can be found inside the dist/lib directory of your PredictionIO source installation directory (if you have built from sources) or the lib directory of your PredictionIO binary installation directory.
Next, you will need to make sure some configuration files from your PredictionIO installation can be found during runtime. Add the conf directory of your PredictionIO installation directory. When asked about categories of the directory, pick Classes.
Finally, you will need to add storage classes. The exact list of JARs that you will need to add depends on your storage configuration. These JARs can be found inside the dist/lib/spark directory of your PredictionIO source installation directory (if you have built from sources) or the lib/spark directory of your PredictionIO binary installation directory.
pio-data-elasticsearch-assembly-0.14.0.jarAdd this JAR if your configuration uses Elasticsearch.
pio-data-hbase-assembly-0.14.0.jarAdd this JAR if your configuration uses Apache HBase.
pio-data-hdfs-assembly-0.14.0.jarAdd this JAR if your configuration uses HDFS.
pio-data-jdbc-assembly-0.14.0.jarAdd this JAR if your configuration uses JDBC. Notice that you must also add any additional JDBC driver JARs.
pio-data-localfs-assembly-0.14.0.jarAdd this JAR if your configuration uses local filesystem.
pio-data-s3-assembly-0.14.0.jarAdd this JAR if your configuration uses Amazon Web Services S3.
Make sure to change all these additions to Runtime scope. The following shows an example that uses the JDBC storage backend with PostgreSQL driver.
Running and Debugging in IntelliJ IDEA
Simulating pio train
Create a new Run/Debug Configuration by going to Run > Edit Configurations.... Click on the + button and select Application. Name it pio train and put in the following:
Main class:
1
org.apache.predictionio.workflow.CreateWorkflow
VM options:
1
-Dspark.master=local -Dlog4j.configuration=file:/<your_pio_path>/conf/log4j.properties -Dpio.log.dir=<path_of_log_file>
Program arguments:
1
--engine-id dummy --engine-version dummy --engine-variant engine.json --env dummy=dummy
Make sure Working directory is set to the base directory of the template that you are working on.
Click the folder button to the right of Environment variables, and paste the relevant values from conf/pio-env.sh in your PredictionIO installation directory. The following shows an example using JDBC and PostgreSQL.
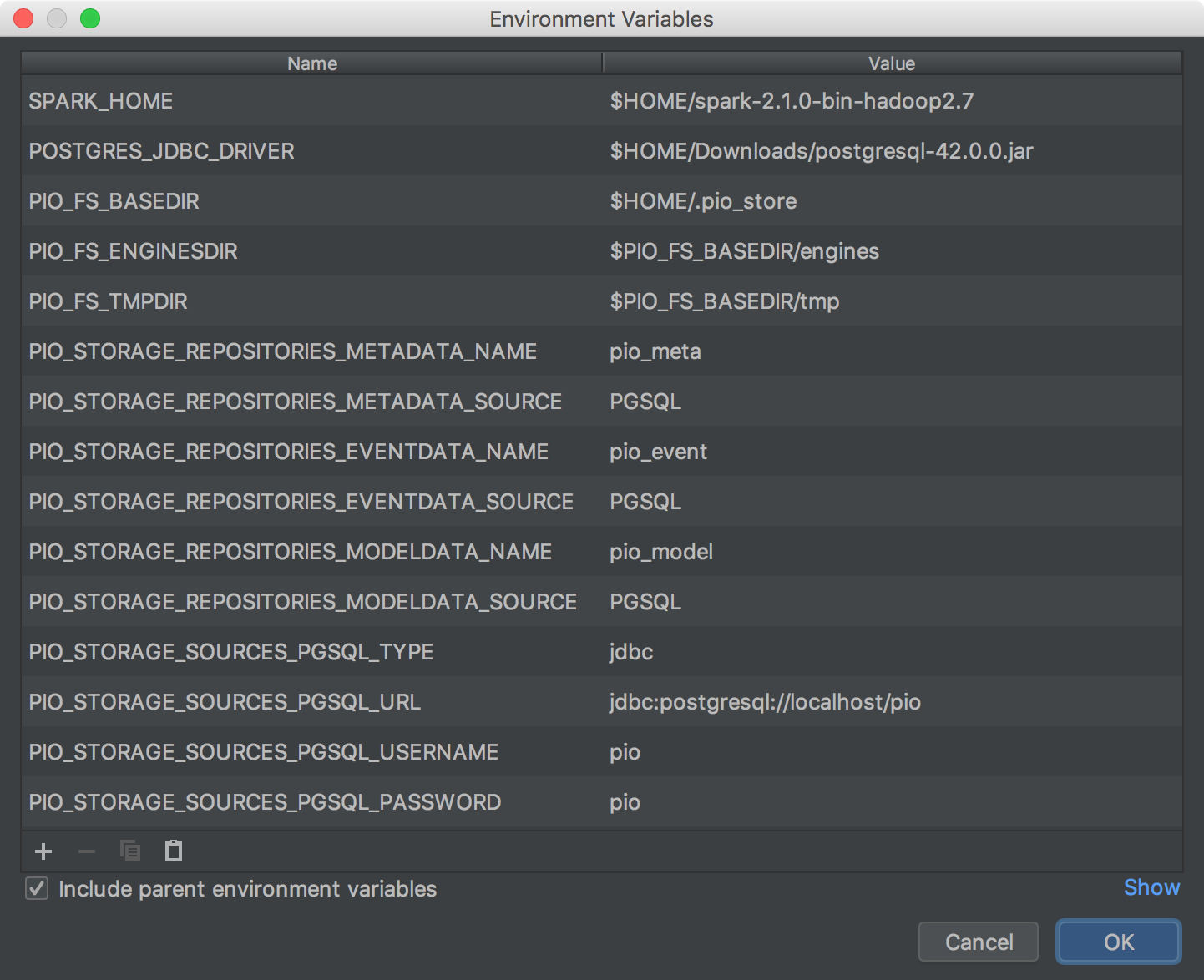
Make sure Include dependencies with "Provided" scope is checked.
The end result should look something similar to this.
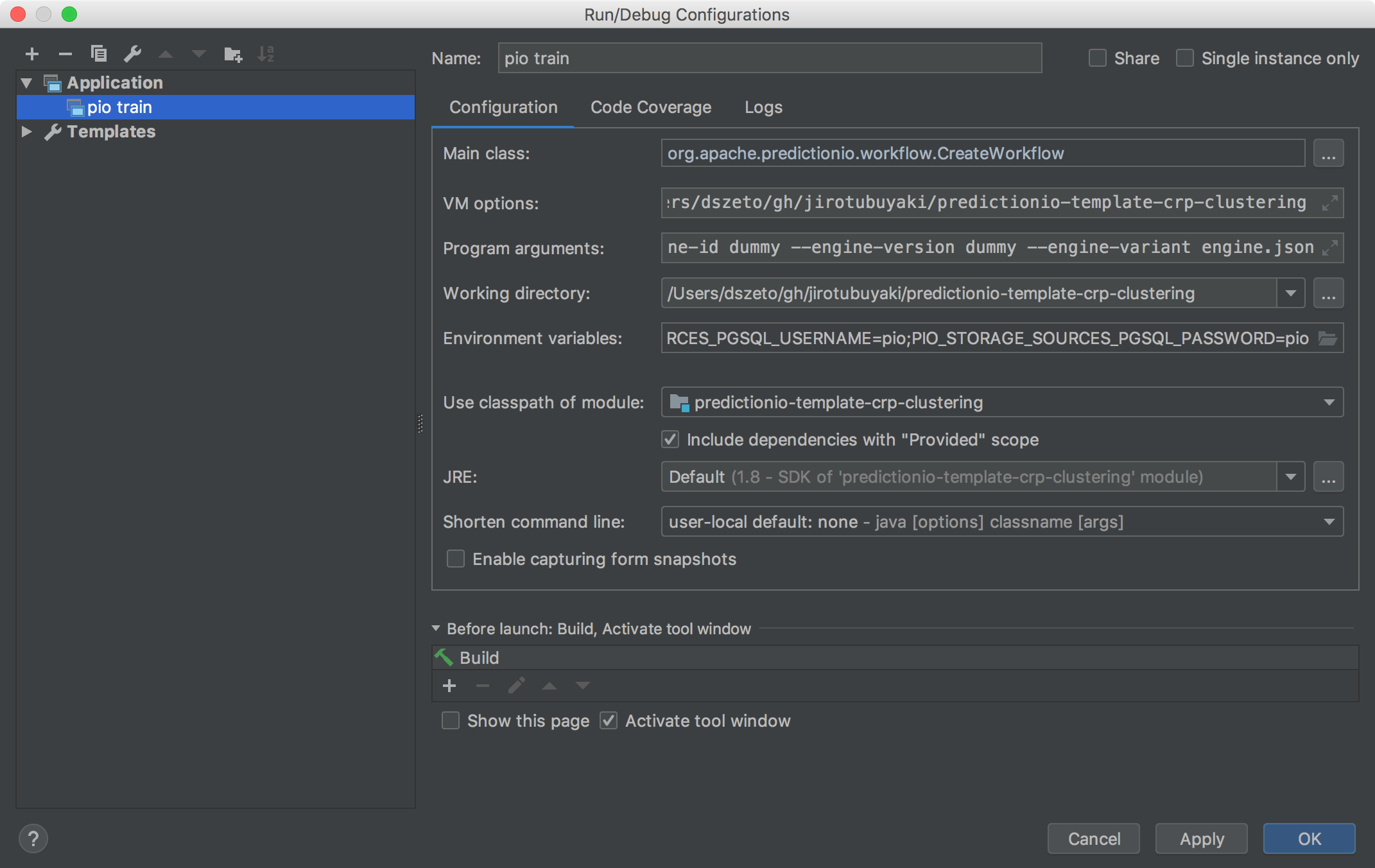
Save and you can run or debug pio train with the new configuration!
Simulating pio deploy
For pio deploy, simply duplicate the previous configuration and replace with the following.
Main class:
1
org.apache.predictionio.workflow.CreateServer
Program Arguments:
1
--engineInstanceId <id_from_pio_train> --engine-variant engine.json
Executing a Query
You can execute a query with the correct SDK. For a recommender that has been trained with the sample MovieLens dataset perhaps the easiest query is a curl one. Start by running or debugging your pio deploy config so the service is waiting for the query. Then go to the "Terminal" tab at the very bottom of the IntelliJ IDEA window and enter the curl request:
1 | curl -H "Content-Type: application/json" -d '{ "user": "1", "num": 4 }' http://localhost:8000/queries.json |
This should return something like:
1 2 3 4 5 6 | {"itemScores":[ {"item":"52","score":9.582509402541834}, {"item":"95","score":8.017236650368387}, {"item":"89","score":6.975951244053634}, {"item":"34","score":6.857457277981334} ]} |