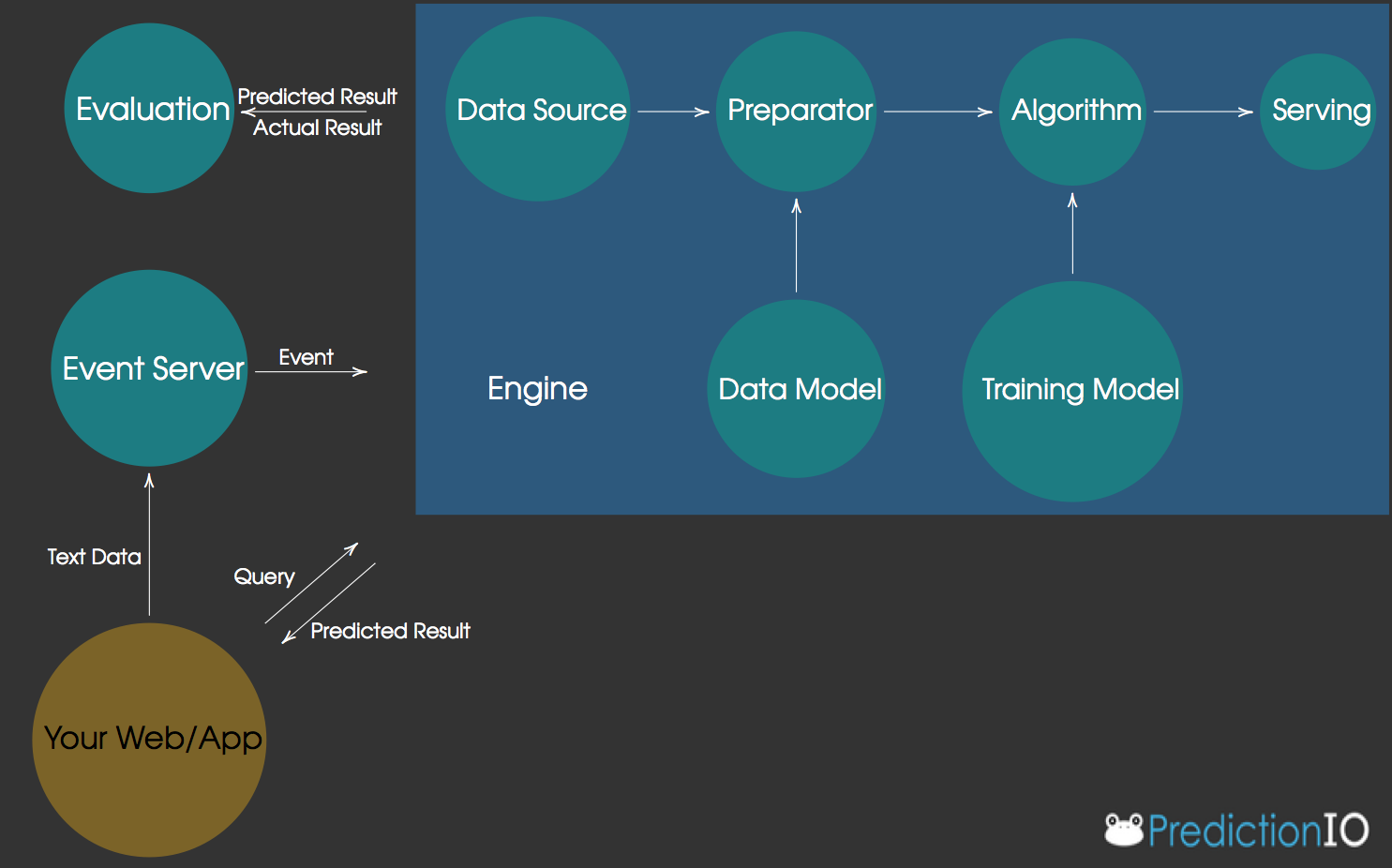
In addition to the DASE components, we also introduce the Data Model and Training Model abstractions. The Data Model abstraction refers to the set of Scala classes dealing with the implementation of modeling choices relating to feature extraction, preparation, and/or selection. For this illustration, this only includes the vectorization of text and t.f.-i.d.f. processing which is entirely implemented in the PreparedData class. The Training Model abstraction refers to any set of classes that individually take in a set of feature observations and output a predictive model. This predictive model is leveraged by the Algorithm component to produce prediction results to queries in real-time. In the engine template, this abstraction is implemented in the NBModel class. Please note that these are conceptual abstractions that are designed to make engine development easier by decoupling class functionality. Keeping these abstractions in mind will help you in the future with debugging your code, and also make it easier to incorporate different modeling ideas into your engine.
The figure below shows a graphical representation of the engine architecture just described, as well as its interactions with your web/app and a provided Event Server:
Training The Model
This section will guide you through the two Training Model implementations that come with this engine template. Recall that the Training Model abstraction refers to an arbitrary set Scala Class that outputs a predictive model (i.e. implements some method that can be used for prediction). The general problem this engine template is tackling is text classification, so that our Training Model abstraction domain is restricted to implementations producing classifiers. In particular, the classification model that is implemented in this engine template is based on Multinomial Naive Bayes using t.f.-i.d.f. vectorized text.